
Data catalogs might be the new Black, but metadata discovery to provision them can be tricky
Data Catalogs
Data catalogs have become a fast growing solution to a critical requirement of an enterprise information management strategy. This is the need to document and understand the types and uses of data across the enterprise application landscape.

Implementing a catalogue of enterprise information sources enhances the value of your data assets
The importance of data catalogs to a data management strategy is emphasised in Gartner’s 2017 Report: ‘Data Catalogs Are the New Black in Data Management and Analytics’. In it they suggest that “Data catalogs enable data and analytics leaders to introduce agile information governance, and to manage data sprawl and information supply chains, in support of digital business initiatives.”
They provide both a place to store information about an organisation’s data assets as well as mechanisms for utilising, enriching, managing and valuing that information. “Metadata is the core of a data catalog. Every catalog collects data about the data inventory and also about processes, people, and platforms related to data. Metadata tools of the past collected business, process, and technical metadata, and data catalogs continue that practice.” Eckerson Group: ‘The Ultimate Guide to Data Catalogs.’
Most large organisations have a wide variety of applications, file stores and home grown systems that they have acquired over the years. These contain data vital to the business. Whilst more enlightened businesses have striven to optimise their understanding and use of data in the past, it is only relatively recently that trying to document and categorise this data has become more mainstream. Much of this is driven by increasing compliance requirements (e.g. the EU GDPR) as well as by the more widespread acceptance of data as an asset whose use can be better optimised.
What do you put in your data catalog?
Rather than contain actual data, a data catalog delivers value by providing a mechanism for technical and business users alike to make use of the metadata, or data structures which underpin their source systems.
This means that one of the early tasks to undertake during the implementation of a data catalog is to identify the sources of that metadata and to start the process of importing it. Any good catalog solution has a range and of scanners and connectors for identifying and mapping metadata from many different sources.
In the Eckerson Group’s, Ultimate Guide to Data Catalogs: “The initial build of a data catalog typically scans massive volumes of data to collect large amounts of metadata. The scope of data for the catalog may include any or all of data lakes, data warehouses, data marts, operational databases, and other data assets determined to be valuable and shareable. Collecting the metadata manually is an imposing and potentially impossible task. The data catalog automates much of the effort using algorithms and machine learning to accomplish the following:
- Find and scan data sets.
- Extract metadata to support data set discovery.
- Expose data conflicts.
- Infer semantic meaning and business terms.
- Tag data to support searching.
- Tag privacy, security, and compliance of sensitive data.”
There are a variety of other methods of capturing metadata, for example via crowd sourcing or catalogue curator based activities.
Not all metadata is equally easy to find and understand
However there are also various classes of system whose valuable metadata is not accessible or usable by those normal methods. In Eckerson’s Ultimate Guide to Data Catalogs they refer to these as “ challenging data sources” Amongst the most difficult of those are the large, complex and often highly customised ERP and CRM packages from SAP, Oracle, Microsoft and others. They hold large amounts of transaction data critical to the success of many thousands of businesses. It is important therefore that their metadata should be included in the data catalogue.
The problem they pose is that there is no meaningful metadata, by which I mean ‘business names’ and descriptions for tables and attributes and no table relationships defined in the database system catalog. The result is that even if a data catalogue scanner reads the schema of the application database, the results are of little value.
Over the past few years we have noticed that even organisations with large Salesforce landscapes are challenged by a lack of mechanisms for identifying and sharing relevant metadata about their systems with solutions such as data catalogs.
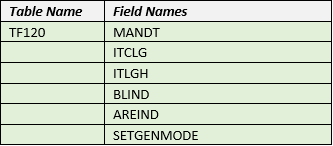
Does this tell the business user or data specialist anything useful?
In addition the tables and attributes contained within their application databases are so numerous as to potentially swamp a data catalog with an excess of metadata which is meaningless without business descriptions, relationships etc. For example being able to import the database schema from the system catalog of an SAP system of over 90,000 tables and 1,000,000 attributes with no ‘business names’, descriptions and relationships into a Data Catalog provides users with nothing to help them navigate and understand the metadata.
To illustrate the point how would a typical data catalog user know what this SAP table TF120 contains from this information?
Of course if you have multiple instances of an ERP such as SAP and their data models are not exactly the same then the problem of understanding their metadata in the data catalog is made worse. Salesforce customers seem to experience this proliferation of instances more often. For example we have worked with one organisation who has 50 separate Salesforce ‘orgs’.
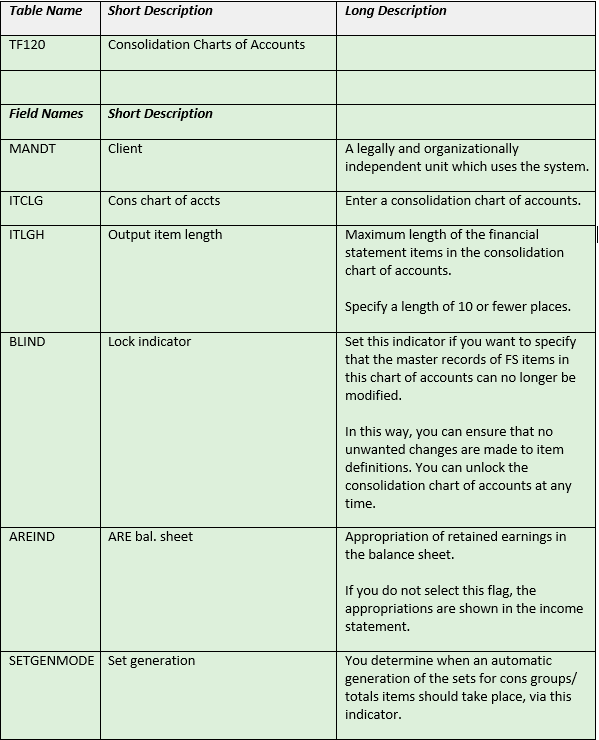
This view of the same table gives business and data users more useful information
What is required is a process for accessing and extracting the rich metadata from wherever it resides, and which then allows for the selection of relevant metadata based on the needs of the business for subsequent import into the data catalog.
This is exactly what our software product Safyr does. It is a unique, specialist self-service metadata discovery product for ERP and CRM packages. It ensures a more a comprehensive and inclusive data catalog solution that is populated with rich metadata from these complex systems. This helps users to find sources of valuable and relevant information more quickly and easily if they come from large and customised packages.
It is also an aid to creating and understanding the lineage of data as it goes on its journey through different stages and systems in an IT infrastructure.
Referring back to the example of Table TF120 it makes much more sense when the user can search for and see it as this
Recommendation
If your organisation is seeking, or engaged in implementing, a data catalog and you have one or more ERP or CRM solutions whose metadata should be included ask the vendors how they propose to achieve this in a cost effective and timely manner. It is also worth confirming how such detailed and complex metadata can be accommodated by their solution. This topic is often overlooked or not fully addressed during the product selection phase.
Where it is discussed a variety of possible approaches may be put forward. These might include using the package vendors own tools, crowdsourcing, engaging internal specialists or external consultants, or even using prebuilt templates. These have some value, however they all provide additional challenges in terms of the amount of time and cost this adds to the project, the level of accuracy as well as physical activity of mapping and importing the metadata into the catalogue.
Some vendors already partner with Silwood and so they will be able to help you with this process. They have realised the value to their customers of providing a comprehensive metadata discovery capability which enables ERP and CRM packages to form part of a data catalogue solution. The technical integration mechanisms may differ from vendor to vendor, however the outcome in terms of speed, accuracy and reliability of metadata import is the same.
Learn more about Safyr for self service metadata discovery for ERP and CRM packages here.

Leave a Reply
Want to join the discussion?Feel free to contribute!